
之前利用了 python 固定每週彙整出所有藥品的各週消耗量,接著就可以計算每個藥品消耗量的指標值,訂出適當的閾值,篩選出指標超過閾值的藥品,形成警示列表。這份報表使用了離群值跟顯著趨勢兩種統計指標作為警示。
離群值
離群值是什麼?
統計上的離群值 (outliers) 指的是超出其類型預期常態的極端數據點,因為各種因素導致的異常數值,例如:輸入錯誤、惡意新增數據、系統異常等等,會嚴重影響統計量的估計值和指標,造成偏差。一般而言,離群值相較於母體或樣本大部分是少數特例,排除後統計量才會比較接近母體或樣本的常態。
在藥品消耗量上,因為消耗量是已經發生過的事實,所以離群值的出現並不是錯誤值,不需要額外排除,反而需要去詳細檢視原因,並藉此調整往後訂購藥品的計畫。所以針對離群值,反而需要早期偵測並篩選出來。
偵測離群值
離群值的偵測方法有好幾種,傳統數學的 3 倍標準差法 ( Z 分數法)、箱型圖法,機器學習的 DBSCAN 、 Isolation Forest ,另外深度學習也有利用 GANs 來檢測離群值的產品。
然而我們需要快速計算出近 1,500 種藥品各 52 週的離群值,機器學習或是深度學習都需要先以已經有的資料訓練模型,或者是經過一些時間的非監督式學習,才能正式使用在資料上。以現有的需求,機器學習或深度學習是耗時並且浪費的,以傳統數學的方法比較合乎效益,雖然這要直接假設所有的消耗量分布都屬於常態分佈。
箱型圖法 (Boxplots) 或稱為盒鬚圖法是計算出資料的各四分位數資料後,再計算第三四分位數 (Q3) 和第一四分數 (Q1) 的差 (四分位距 IQR) ,如果資料點在臨界四分位數 (Q3 或 Q1) 外 1.5 倍的 IQR ,該資料點就是離群值。
例如,假設有一筆資料 [0, 1, 2, 3, 10, 20, 30, 600, 9000],各統計量如下:

- Q1 = (1+2)/2 = 1.5
- Q2 = 10
- Q3 = (30+600)/2 = 315
- 四分位距 IQR = 315-1.5 = 313.5
- 下限 = 1.5-1.5×313.5 = -468.75
- 上限 = 315+1.5×313.5 = 785.25
也就是說, 9000 這筆資料已經超過了上限 785.25 ,視為該筆資料的離群值。
而標準差法是利用常態分佈的資料機率分布在平均數正負三個標準差內的為 99.7% ,換句話說,在三個標準差外的資料機率只有 0.15% 可以視為離群值。

一樣的例子,資料 [0, 1, 2, 3, 10, 20, 30, 600, 9000],各統計量如下:
- 平均值 = 1074
- 母體標準差 = 2808.32
- 下限 = 1074-3×2808.32 = -7350.96
- 上限 = 1074+3×2808.32 = 9498.96
該筆資料全部都落在 -7350.96 到 9498.96 之間,沒有離群值。
程式實作
實際計算藥品的消耗量後,發現箱形圖法對於離群的容忍範圍比較小,因為離群藥品需要透過藥師再次詳細檢核,希望被篩選出的數量能夠維持在 20~30 個左右,因此選擇了標準差法,而且 3 倍的標準差以外視為離群值的資料量還是過大,微調之後改採用 4 倍標準差。
同時資料區間取一年的每週消耗量,並無法準確代表最近這幾週的資料,也是經過微調後,僅取後 12 個資料點。但為了避免後續需要再次調整,所以先把閾值變數拉到程式最上面。
import pandas as pd
import numpy as np
# 閾值變數
data_range = 12 # 只取最近的 12 個資料點就好
std_times = 4 # 4 倍標準差以外的視為離群值
引入檔案後,整理資料表頭:
# 引入上次的中繼檔案
df = pd.read_csv('暫存.csv')
df = df.iloc[:,-data_range:]
# 原始檔案的 column name 都是日期,重新換成固定的名字 data_x 比較好操作
header = [f'data_{x}' for x in range(0, data_range)]
df = df.set_index('藥品代碼')
df.columns = header
排除12個資料都是0的品項,分析沒有意義,也不需要列出警訊:
df = df.loc[df.sum(axis=1)!=0]
計算第 1 個到第 11 個的統計值, .mean() 和 .std() 的預設值都是 axis=0 計算直欄的結果,所以要代入 axis=1 。
而 .std() 預設的自由度 ddof 是 1,因為資料屬於母體總數,而不是抽樣樣本數,所以自由度設為 0 就好。
# ppl = population
ppl = [f'data_{x}' for x in range(0, data_range-1)]
df['ppl_mean'] = df[ppl].mean(axis=1)
df['ppl_std'] = df[ppl].std(axis=1, ddof=0)
# 計算上下限
df['upper_std_times'] = df['ppl_mean'] + std_times * df['ppl_std']
df['lower_std_times'] = df['ppl_mean'] - std_times * df['ppl_std']
列出大於或小於限制的藥品,並且加入排序依據後輸出 csv 檔:
df.loc[df[f'data_{data_range-1}']>df['upper_std_times'], 'outlier'] = 'greater'
df.loc[df[f'data_{data_range-1}']<df['lower_std_times'], 'outlier'] = 'less'
# 排序依據為
df['outlier_rate'] = (df[f'data_{data_range-1}']-df['ppl_mean']) / df['ppl_std']
df['outlier_rate'] = df['outlier_rate'].abs().replace(np.inf,np.nan)
df = df.loc[df['outlier'].notna()]
df = df.sort_values(by=['outlier_rate','藥品代碼'])
df.to_csv('outliers.csv')
這個檔案接下來就交給 php 讀取再丟入 chartjs 製圖。
顯著趨勢
當資料屬於時間序列資料的時候,數學公式就默認了資料具有趨勢值,因此建立 SARIMAX 模型或是 prophet 模型時,就可以利用數學方法分離並單獨顯示趨勢性,並且利用加性迴歸模型或是乘性迴歸模型進行參數的調整。
問題跟檢測離群值的時候一樣,今天的需求是快速的篩選出 1,500 種的藥品,機器學習耗費的效能與時間太多,而且 SARIMAX 模型或是 prophet 模型都還要逐個藥品進行眾多參數的調整,雖然有 Auto-ARIMAX/SARIMAX 這種產品可以自動調整參數,但後來還是決定使用傳統數學的簡單線性迴歸分析來檢查趨勢性。
簡單線性迴歸
簡單線性迴歸分析網路上或教科書上可以找到很多嚴謹的定義,用我自己的話解釋就是,找出兩組資料之間的關係。例如說週序:消耗量的資料組,分布在二維坐標上,以週序為 x 軸, y 軸是消耗量,目標就是畫出一條 ${y}$=$\beta_0$+$\beta_1 {x}$ 的迴歸直線,找到 $\beta_0$ 和 $\beta_1$ 。
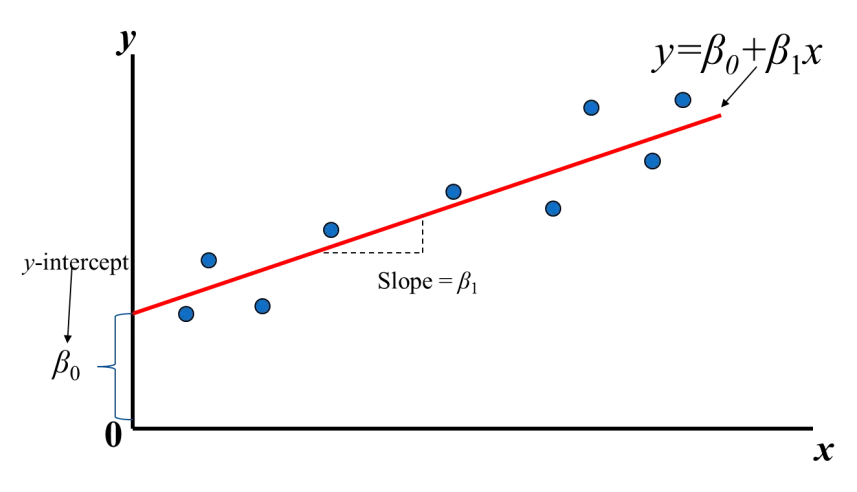
迴歸直線係數的算法就不再贅述,可以利用高中的最小平方法,或是大學微積分求得。 Python 也有專門用來進行科學運算的 SciPy 函式庫來計算迴歸直線的各項參數,先把它裝起來:
pip install scipy
p-value 和 R-squared
另外一個很重要的步驟是檢查這條直線有沒有辦法用來描述資料組,如果資料組之間關係很薄弱,或是直線和資料組的關係很薄弱,直線都無法用來描述資料組。有兩個統計值可以用來檢查資料組之間和直線的關係,分別是 p-value 和 R-squared 。
- p-value :用以表達 x 軸資料和 y 軸資料的關係。當 p-value 趨近於 0 時,兩組資料顯著有關,而趨近於 1 時,則不太有關。
- R-squared :用以表達畫出直線與兩組資料的吻合程度。當 R-squared 趨近於 1 時,直線和兩組資料非常吻合,而趨近於 0 時,則不太吻合。
所以目標是要找到 p-value 趨近於 0 同時 R-squared 趨近於 1 的資料和迴歸直線,以我們的資料週序:消耗量而言,表示消耗量與週序之間相關並且可以找到一條直線描述兩者之間的關係,這條直線又可以說是週序的趨勢直線。
問題來了!我們從機器學習的多參數設計,簡化成傳統數學的線性迴歸,卻還有兩個統計值需要分別建立閾值,還是太多了,還好藥品的資料全部都是母體資料,而且用 p-value 和 R-squared 作圖之後發現 p-value 趨近於 0 的資料剛好就是 R-squared 趨近於 1 的資料,如此一來我們只需設定其中一個閾值就好。

- p-value 不顯著但 R-squared 很吻合:表示資料組之間不太有關聯性,或者是抽樣的資料組無法代表整體情形,但有可能這次取到的資料點很完美的吻合直線。
- p-value 很顯著但 R-squared 不吻合:表示資料組之間關聯性很強,但是迴歸分析的方法可能不是直線,也許是多元直線或是其他曲線。
程式實作
前面有提過了,我們需要安裝一個函式庫 SciPy 進行科學計算:
pip install scipy
跟離群值實作一樣,將閾值變數拉到程式最上面方便日後調整,變數 r_squared 依照結果調整後發現 0.7 是最好的數值:
import pandas as pd
from scipy import stats
# 閾值變數
data_range = 12 # 只取最近的 12 個資料點就好
r_squared = 0.7
引入檔案,整理資料表頭:
# 引入上次的中繼檔案
df = pd.read_csv('暫存.csv')
df = df.iloc[:,-data_range:]
# 原始檔案的 column name 都是日期,重新換成固定的名字 data_x 比較好操作
header = [f'data_{x}' for x in range(0, data_range)]
df = df.set_index('藥品代碼')
df.columns = header
利用 stats.linregress(x, y) 的方法求得各項統計值,這個方法會返回一個物件:
stats.linregress(x, y) = {
# 迴歸線的斜率
'slope': float,
# 迴歸線的截距
'intercept': float,
# 相關係數 (correlation coefficient)
'rvalue': float,
# 使用 Wald 檢定虛無假設是斜率為 0 的假說檢定下的 p-value
'pvalue': float,
# 假設殘差為常態性,斜率的標準誤
'stderr': float,
# 假設殘差為常態性,截距的標準誤
'intercept_stderr': float
}
另外我們會使用 .apply() 搭配匿名函式 lambda 一起使用。
先分開來看, lambda 就是省略命名的自訂函式,例如以下的結果:
def square(x):
return x**2
a = square(3)
# 結果為 9
b = (lambda x: x**2)(3)
# 結果為 9
而 DataFrame 的 .apply() 則是會依序將 DataFrame 的值抓出來經過 .apply() 內的函式計算後返回 DataFrame ,結合一下上面的例子:

合一起就是,把被計算欄的值依序抓出當成 x ,計算 x**2 後將結果丟到結果欄:
df['結果欄'] = df['被計算欄'].apply(lambda x: x**2)
因為我們時間資料的 x 軸資料是週序,但是 stats.linregress(x, y) 的 x 軸資料必須是數值,還好所有藥品的週序資料都是固定統一的,而且是差 7 天的等差級數,可以直接把週序換成 [1, 2,..., 12] 差 1 的等差級數,結果一樣不會變:
# 兩組資料都換成 list
x = [x for x in range(data_range)]
df['y'] = df[header].values.tolist()
# 計算統計值
df['slope'] = df['y'].apply(lambda y: stats.linregress(x, y)[0])
df['intercept'] = df['y'].apply(lambda y: stats.linregress(x, y)[1])
df['r_squared'] = df['y'].apply(lambda y: stats.linregress(x, y)[2] ** 2)
# 分類
df.loc[(df['r_squared']>=r_squared) & (df['slope'] >= 0), 'trend'] = 'rise'
df.loc[(df['r_squared']>=r_squared) & (df['slope'] < 0), 'trend'] = 'fall'
另外加入排序依據和增加一點資料給 chartjs ,這個之後製作圖表會提到:
# 排序依據
df['trend_rate'] = (df[f'data_{data_range-1}'] - df['data_0'] ).abs() / data_range
# 為了 chartjs 的資料:迴歸線的線頭和線尾
df['rline_head'] = df['intercept'] - df['slope']
df['rline_tail'] = df['intercept'] + (data_range+1) * df['slope']
最後輸出檔案就完成了:
df = df.loc[df['trend'].notna()]
df = df.sort_values(by=['trend_rate','藥品代碼'])
df.to_csv('trend.csv')
圖表設計
可以把上面兩個程式合併在一起後直接輸出成一個 csv 檔案,整理之後標題大概會是這樣:
[
'藥品代碼':'文字資料',
# 各消耗量資料點:'數字'
'data_0','data_1','data_2','data_3','data_4','data_5','data_6','data_7','data_8','data_9','data_10','data_11',
# 離群指標
'outlier':'greater'或是'less',
'outlier_rate':'數字',
'ppl_mean':'數字',
# 趨勢指標
'trend':'rise'或是'fall',
'trend_rate':'數字',
'rline_head':'數字',
'rline_tail':'數字'
]
用 php 讀取檔案後丟給 chartjs 生成圖表,圖表的設計需要能夠反映重點,大概設計如下:

- x 軸設定為週序, y 軸為消耗數量
- x 軸為 Category Axis ,並且在頭尾增加一欄空白的資料 (NaN)
- x 軸的顯示範圍最小值從 data_0 開始,最大值到 data_11 ,頭尾空欄不顯示
- y 軸為 Cartesian Axes ,最小值為 0 ,最大值由資列決定
- 不顯示 x 軸和 y 軸所有的刻度,詳細資料直接建立超連結連結他頁
- 不顯示所有格線
- 不顯示圖示和 tooltips
這些設定直接用一個固定變數代入 chartjs 的 option:
<script>
const chart_option = {
aspectRatio: 5,
animation: false,
scales: {
x: {
min: 1, // 若為 0 則會顯示頭欄空格
max: <?= $data_range; ?>,
ticks: {
display: false,
},
grid: {
display: false,
drawTicks: false,
}
},
y: {
min: 0,
ticks: {
display: false
},
grid: {
display: false,
drawTicks: false,
},
beginAtZero: true
}
},
plugins: {
legend: {
display: false
},
tooltip: {
enabled: false
}
}
};
</script>
離群值
離群值圖表的資料,希望離群值的 bar 顏色會因為高於或低於限制顯示不同的顏色。所以第一步就會使用 php 的 if 功能進行圖表顏色的設定。
也就是 if ( $outlier == "greater" ) 的時候:
 由圖上可以知道我們需要設定三種資料:
由圖上可以知道我們需要設定三種資料:
- 藍色 bar : [
NaN, data_0, data_1, … , data_10,NaN,NaN] - 紅色 bar : [
NaN,NaN,NaN, … ,NaN, data_11,NaN] - 灰色 line : [平均值,
NaN,NaN, … ,NaN,NaN, 平均值]
因為 x 軸是使用 Category Axis ,灰色 line 的頭尾會從空欄中的正中央開始及結束,所以上面才會藉由調整 x 軸的最大值和最小值來保留可視範圍,去除不美觀的線頭和線尾。
而 if ( $outlier == "less" ) 的時候,修正第二條資料的顏色:

- 藍色 bar : [
NaN, data_0, data_1, … , data_10,NaN,NaN] - 綠色 bar : [
NaN,NaN,NaN, … ,NaN, data_11,NaN] - 灰色 line : [平均值,
NaN,NaN, … ,NaN,NaN, 平均值]
資料確認後,就著手來進行程式的部份:
PHP
$nanhead = "[";
for ($i = 0; $i < $data_num; $i++) $nanhead .= "NaN,";
$nantail = ",NaN]";
$nanbody = ",";
for ($i = 0; $i < $data_num; $i++) $nanbody .= "NaN,";
Chartjs
<script>
const chart_<?= $藥品代碼; ?> = new Chart(document.getElementById('chart_<?= $藥品代碼; ?>').getContext('2d'), {
data: {
labels: ['頭', 0, 1, 2, ... , 11, '尾'],
datasets: [
{ // 藍色 bar
type: 'bar',
data: <?php $ppl = "[NaN,";
for ($i = 10; $i < $data_num+9; $i++) $ppl .= $data_[$i].",";
echo $ppl."NaN,NaN]";
?>,
backgroundColor: 'rgba(2, 117, 216, 0.6)',
borderWidth: 1,
stack: 'bar'
},
<?php if ($outlier=="greater") : ?>
{ // 紅色 bar
type: 'bar',
data: <?= $nanhead.$row[$data_num+9].$nantail; ?>,
backgroundColor: 'rgba(220, 53, 69, 0.8)',
borderWidth: 1,
stack: 'bar'
},
<?php elseif ($outlier=="less") : ?>
{ // 綠色 bar
type: 'bar',
data: <?= $nanhead.$row[$data_num+9].$nantail; ?>,
backgroundColor: 'rgba(25, 135, 84, 0.8)',
borderWidth: 1,
stack: 'bar'
},
<?php endif; ?>
{ //平均線
type: 'line',
data: <?= "[".$row[5].$nanbody.$row[5],"]"; ?>,
borderColor: 'rgba(108, 117, 125, 0.4)',
spanGaps: true,
pointRadius: 0,
borderDash: [5, 5]
},
]
},
options: chart_option
});
</script>
顯著趨勢
如同離群值的圖表設定,當 if ( $trend == "rise" ) 的時候:

- 藍色 bar : [
NaN, data_0, data_1, … , data_10, data_11,NaN] - 紅色 line : [迴歸線頭,
NaN,NaN, … ,NaN,NaN, 迴歸線尾]
if ( $trend == "fall" ) 改迴歸線顏色:

- 藍色 bar : [
NaN, data_0, data_1, … , data_10, data_11,NaN] - 綠色 line : [迴歸線頭,
NaN,NaN, … ,NaN,NaN, 迴歸線尾]
程式的部份:
Chartjs
<script>
const chart_<?= $藥品代碼; ?> = new Chart(document.getElementById('chart_<?= $藥品代碼; ?>').getContext('2d'), {
data: {
labels: ['頭', 0, 1, 2, ... , 11, '尾'],
datasets: [
{ // 藍色 bar
type: 'bar',
data: <?php $ppl = "[NaN,";
for ($i = 10; $i < $data_num+9; $i++) $ppl .= $data_[$i].",";
echo $ppl."NaN,NaN]";
?>,
backgroundColor: 'rgba(2, 117, 216, 0.6)',
borderWidth: 1,
stack: 'bar'
},
{ // data_11 一樣是藍色的
type: 'bar',
data: <?= $nanhead.$row[$data_num+9].$nantail; ?>,
backgroundColor: 'rgba(2, 117, 216, 0.6)',
borderWidth: 1,
stack: 'bar'
},
<?php if ($trend=="rise") : ?>
{ // 紅色 line
type: 'line',
data: <?= "[".$rline_head.$nanbody.$rline_tail,"]"; ?>,
borderColor: 'rgba(220, 53, 69, 0.8)',
spanGaps: true,
pointRadius: 0,
borderDash: [5, 5]
},
<?php elseif ($trend=="fall") : ?>
{ // 綠色 line
type: 'line',
data: <?= "[".$rline_head.$nanbody.$rline_tail,"]"; ?>,
borderColor: 'rgba(220, 53, 69, 0.8)',
spanGaps: true,
pointRadius: 0,
borderDash: [5, 5]
},
<?php endif; ?>
]
},
options: chart_option
});
</script>
成果
引入其他資料並且迭代在網頁上之後就完成啦!
